
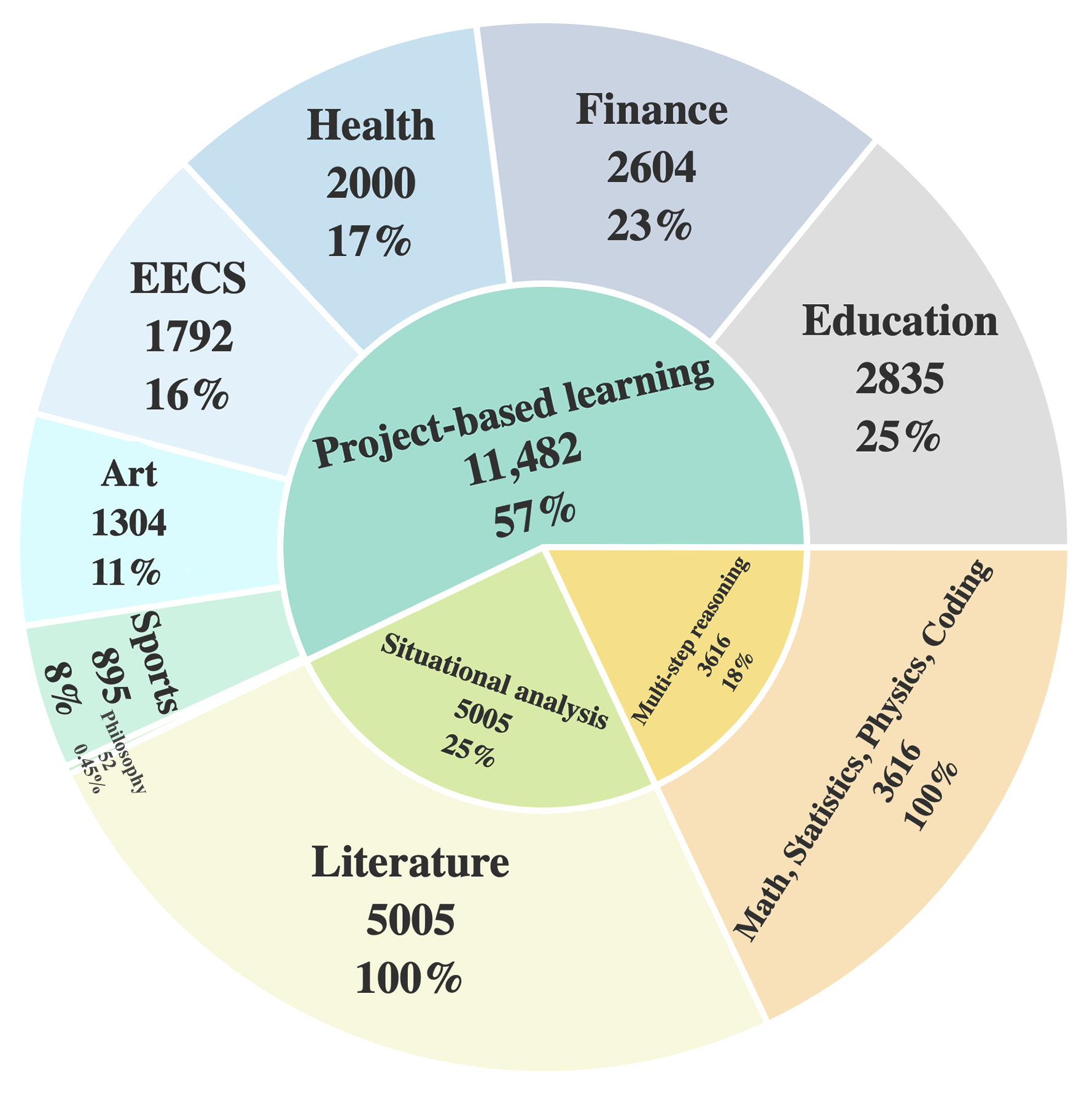


MMIE provides a systematic evaluation of existing open-source LVLMs supporting interleaved multimodal input and output interleaved LVLMs, along with the integration of state-of-the-art LVLMs and text-to-image generative models integrated LVLMs. To view detailed results, please see the paper. Leaderboard is also available on huggingface.
Scores on MMIE benchmark.
| Model | Model Type | Situational analysis | Project-based learning | Multi-step reasoning | AVG |
|---|---|---|---|---|---|
| MiniGPT-5 | Interleaved LVLM | 47.63 | 55.12 | 42.17 | 50.92 |
| EMU-2 | Interleaved LVLM | 39.65 | 46.12 | 50.75 | 45.33 |
| GILL | Interleaved LVLM | 46.72 | 57.57 | 39.33 | 51.58 |
| Anole | Interleaved LVLM | 48.95 | 59.05 | 51.72 | 55.22 |
| GPT-4o | Openjourney | Integrated LVLM | 53.05 | 71.4 | 53.67 | 63.65 |
| GPT-4o | SD-3 | Integrated LVLM | 53 | 71.2 | 53.67 | 63.52 |
| GPT-4o | SD-XL | Integrated LVLM | 56.12 | 73.25 | 53.67 | 65.47 |
| GPT-4o | Flux | Integrated LVLM | 54.97 | 68.8 | 53.67 | 62.63 |
| Gemini-1.5 | Openjourney | Integrated LVLM | 48.08 | 67.93 | 60.05 | 61.57 |
| Gemini-1.5 | SD-3 | Integrated LVLM | 47.48 | 68.7 | 60.05 | 61.87 |
| Gemini-1.5 | SD-XL | Integrated LVLM | 49.43 | 71.85 | 60.05 | 64.15 |
| Gemini-1.5 | Flux | Integrated LVLM | 47.07 | 68.33 | 60.05 | 61.55 |
| LLAVA-34b | Openjourney | Integrated LVLM | 54.12 | 73.47 | 47.28 | 63.93 |
| LLAVA-34b | SD-3 | Integrated LVLM | 54.72 | 72.55 | 47.28 | 63.57 |
| LLAVA-34b | SD-XL | Integrated LVLM | 55.97 | 74.6 | 47.28 | 65.05 |
| LLAVA-34b | Flux | Integrated LVLM | 54.23 | 71.32 | 47.28 | 62.73 |
| Qwen-VL-70b | Openjourney | Integrated LVLM | 52.73 | 71.63 | 55.63 | 64.05 |
| Qwen-VL-70b | SD-3 | Integrated LVLM | 54.98 | 71.87 | 55.63 | 64.75 |
| Qwen-VL-70b | SD-XL | Integrated LVLM | 52.58 | 73.57 | 55.63 | 65.12 |
| Qwen-VL-70b | Flux | Integrated LVLM | 54.23 | 69.47 | 55.63 | 63.18 |